
In the fast-paced world of data management, engineers seek solutions that offer both power and performance. Enter ScyllaDB, a cutting-edge technology poised to revolutionize how we handle large-scale data. Let’s dive deep into the technical intricacies of Scylla and understand why it’s a game-changer for engineers.
I. Introduction to ScyllaDB
ScyllaDB is an open-source distributed NoSQL database, rewritten in C++ based on Apache Cassandra written in Java. It supports the same protocols as Cassandra (CQL and Thrift) and the same file formats (SSTable), but is a completely rewritten implementation, using the C++20 language replacing Cassandra’s Java. It is engineered with the following key features:
High Scalability:
- Vertical scaling: ScyllaDB allows adding new nodes to the cluster.
- Horizontal scaling: It permits adding resources on existing nodes in the cluster (CPU/RAM).
High Availability:
- No Master-Slave Mechanism: All nodes play equal roles in data processing, ensuring cluster accessibility even if one or more nodes fail. It exhibits fault tolerance and self-recovery capabilities.
High performance:
- Low Latency: Achieved through various optimization techniques, it runs close to the hardware provided (CPU, RAM, etc.).
II. Architecture
1. Ring Token Architecture
Scylla utilizes a ring structure to manage and distribute data across nodes in the cluster. The Ring Token decides how data is distributed among nodes.
Each node in a ScyllaDB cluster is assigned a token range, distributed on a virtual circle called a ring.
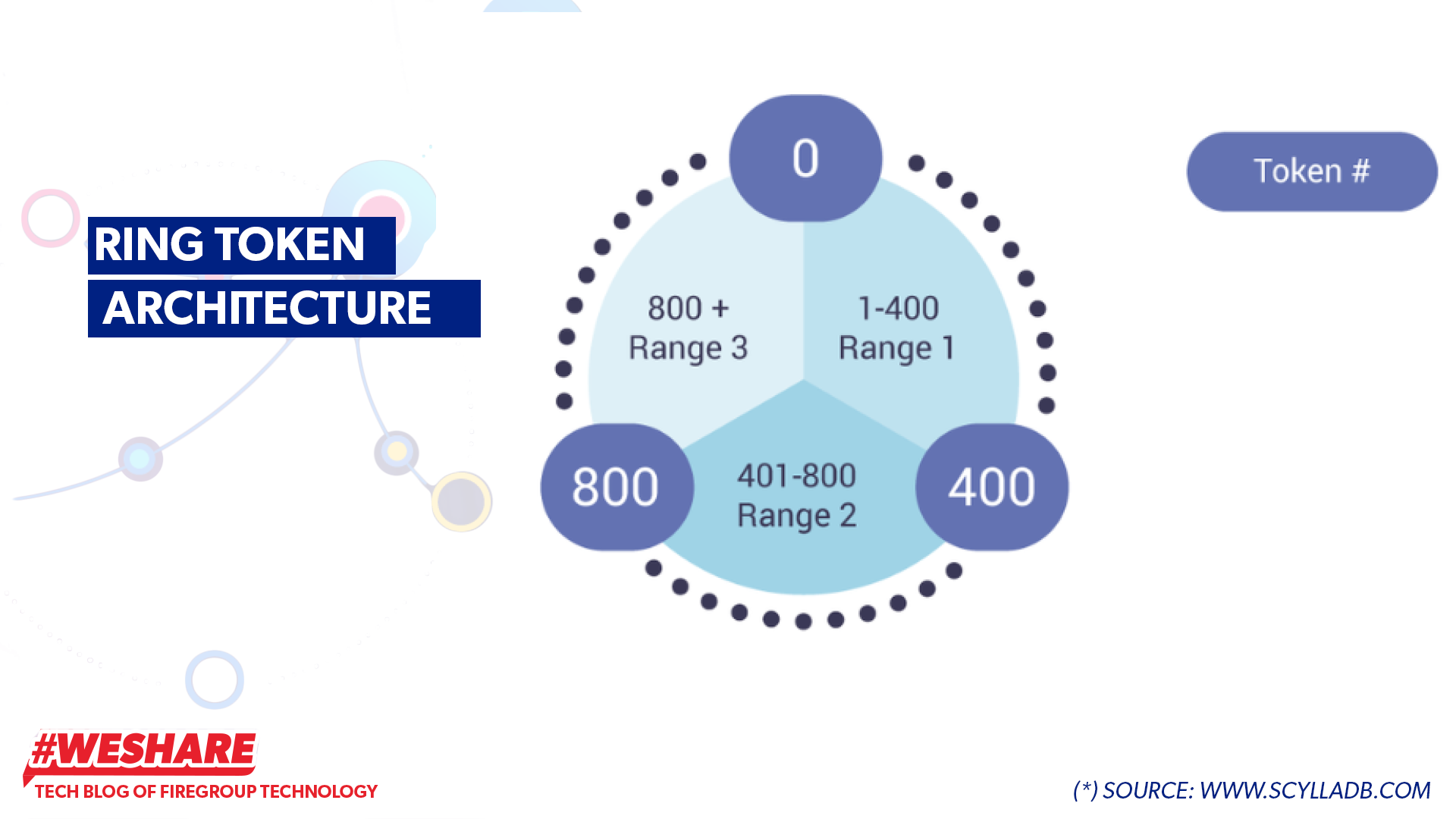
Ring Token Architecture
When data (row) is written into the cluster, Scylla employs consistent hashing algorithms based on the partition key to hash and create a token, determining where the data will be stored across nodes in the cluster. Each node manages a portion of the data within the token ring.
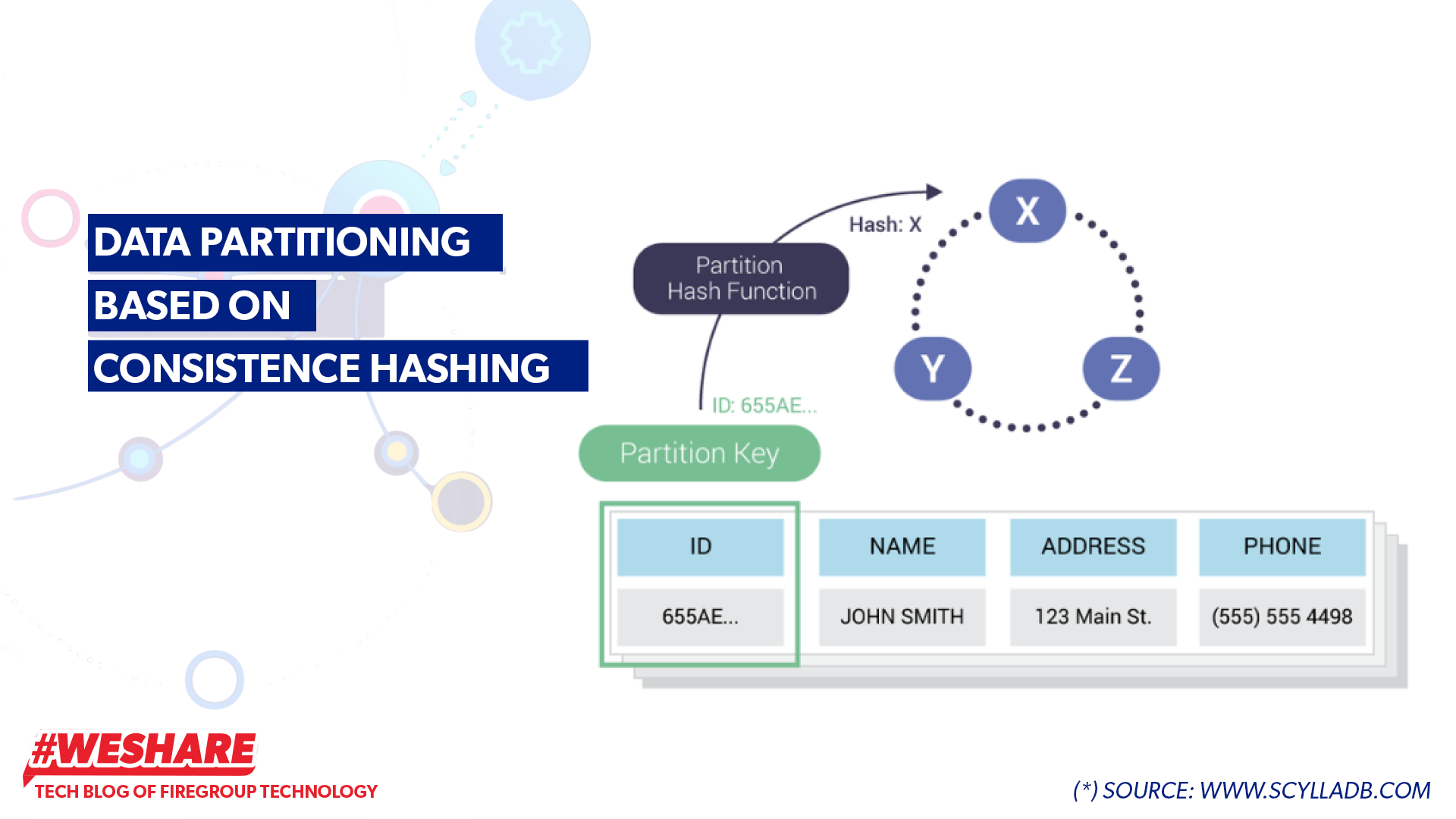
Data partitioning based on consistence hashing
Each ScyllaDB node in the cluster operates independently, and horizontally and does not share physical resources like CPU, Memory, or storage with other nodes.
The computational unit of ScyllaDB is called a shard, with the formula: 1 CPU Core = 1 shard. Each shard does not share RAM or CPU with other shards. A shard in ScyllaDB is an independent processing unit, running on a separate CPU thread and managing a portion of the database data.
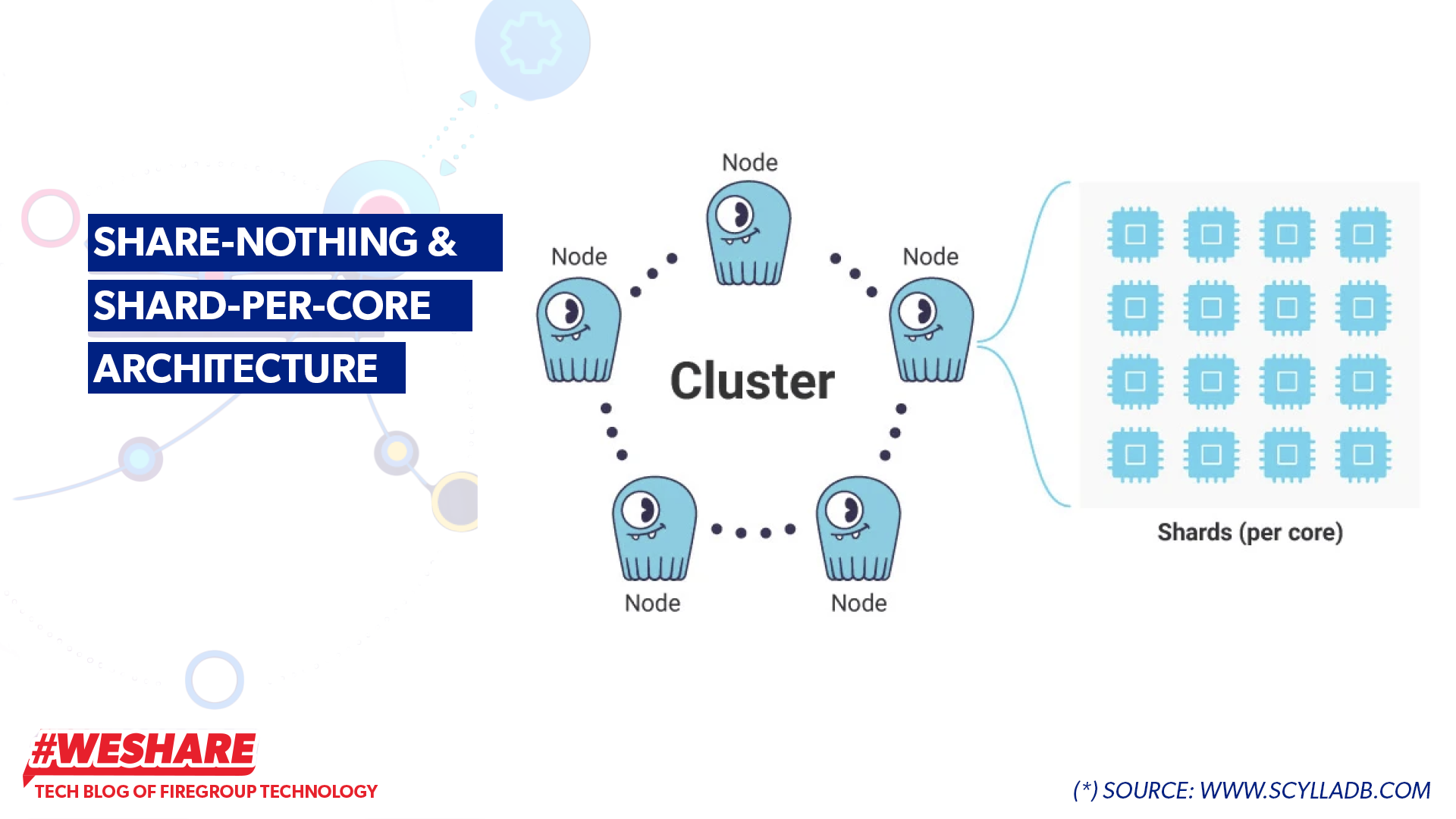
Share-Nothing & Shard-Per-Core Architecture
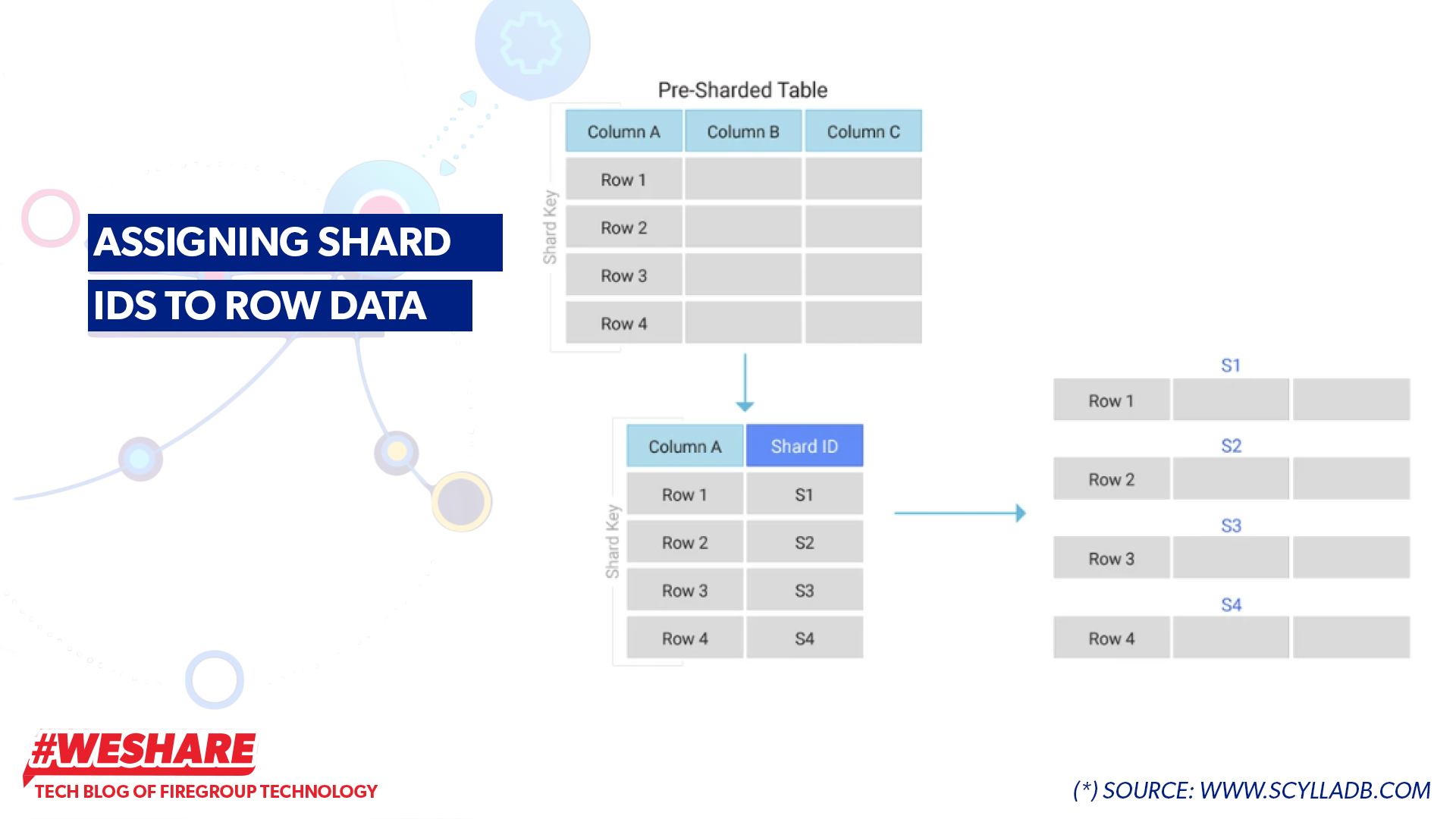
Assigning Shard IDs to Row Data
For Example:
- When initializing a Scylla cluster with 3 nodes, each node is assigned a unique token. These tokens are organized into a virtual ring called the token ring.
- When writing data to a table, with the key ID as 655AE… and values NAME, ADDRESS, PHONE (2), Scylla uses consistent hashing to create a token hash to determine which node in the cluster and which shard will store the data. For example, Scylla determines to store the inserted row at node (X) and shard 2.
- When reading data, Scylla will know the token hash of key ID 655AE,… to identify which node and shard the data is allocated to. It then uses that shard to process it.
3. Internal Cache Architecture
When writing data to a cluster, for the write process to be considered successful, the data must first be written to the commit log. If the commit log write is successful, the data will be transferred to the Memtable located in RAM. At this point, the data has been stored in the cache to serve queries reading the data just written to the cluster (Figure: Internal Cache Architecture (1)).
When the Memtable becomes full or expires, ScyllaDB will push the data down to SStable (3) (Figure: Internal Cache Architecture (1)) -> Then, the old Memtable will be deleted, and a new Memtable will be created.

Internal Cache Architecture (1)
Scylla regularly brings some frequently accessed data from SSTables up to the RAM cache to increase query speed (See details in Figure: Internal Cache Architecture (2)).
If there is a cache hit, the data will be read and returned directly from the cache in RAM; if there is a cache miss, SStables will be used to return the result, and this data will be cached again in RAM to serve subsequent queries. If there are many tasks requiring a lot of RAM, part of the cache may be evicted to free up memory. When the RAM becomes unused again, the cache will be loaded back from the SSTables.
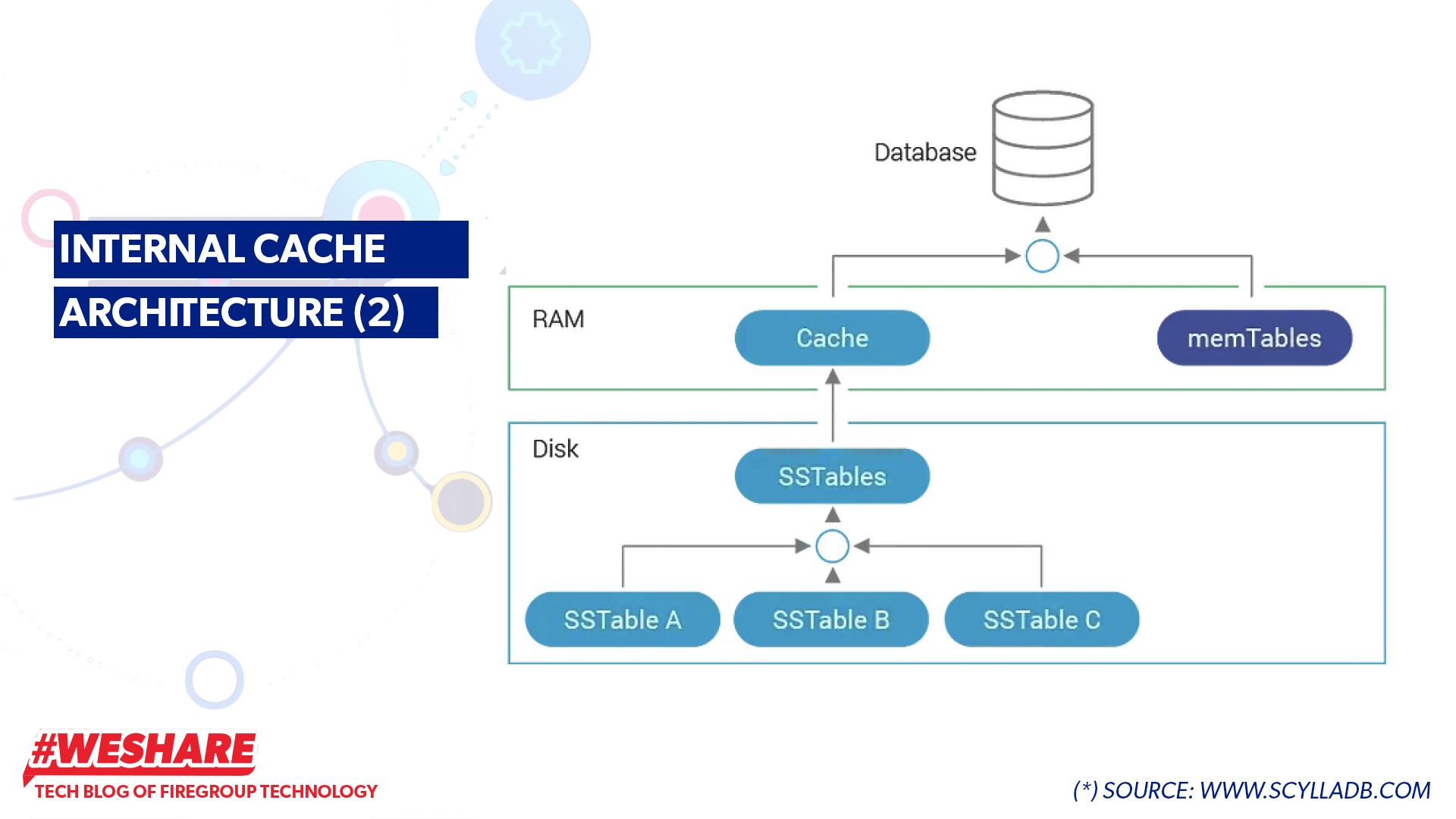
Internal Cache Architecture (2)
III. Key Concepts in ScyllaDB
- Cluster: A minimum of 3 ScyllaDB nodes.
- Node: A ScyllaDB instance running on a server or container.
- Shards: Independent processing units within each node of the cluster.
- Keyspace: A place containing tables and replicas across one or multiple nodes.
- Table: Where data is stored, including rows and columns.
- Rows/Columns: Data stored in rows and columns within a table.
- Partition Key: A primary key used by ScyllaDB for a consistent hashing algorithm to distribute data to a node.
- Commitlog: Stored on disk, CommitLog records all write operations before they are applied to the Memtable. In case of failures, CommitLog can be used to recover lost or corrupted data.
- Memtable: A temporary memory storage in RAM used to accelerate access to the latest data from read operations. The Memtable is flushed to SStable when it expires or becomes full, creating a new Memtable.
- SStable (Sorted String Table): A table-like data structure used to store data on disk in ScyllaDB after data is flushed from the Memtable through the flush process.
IV. Data Replication
Since ScyllaDB is a distributed database system, data loss can occur if a node goes down or fails without the presence of Data Replication.
Data replication is a crucial part of ensuring system availability and resilience in node failure situations within a cluster and to improve data read performance. ScyllaDB introduces two important concepts:
1. Replication Factor:
- When data is stored in ScyllaDB, it is duplicated and stored on multiple nodes across the cluster with a specified “replication factor” (often 3). This means that each data record will have at least 3 copies stored on 3 different nodes.
- If a node fails or becomes inactive, data replicas still exist on other nodes, and the system can continue to serve read/write requests from the remaining nodes. When the failed node returns to operation, data will be synchronized from the replicas on other nodes.
2. Consistency Level (CL):
- CL is an important concept related to the number of successful data replicas required (acknowledged) in a read or write operation for that read/write operation to be considered successful.
- ScyllaDB provides different consistency levels such as:
- ONE: Requires only 1 node in the cluster to return data or acknowledge successful write.
- QUORUM: Requires at least a majority of nodes (quorum) in the cluster to return data or acknowledge successful write. This is the default level in ScyllaDB.
- ALL: Requires all nodes storing data replicas to return data or acknowledge successful write.
- Higher consistency levels (QUORUM, ALL, LOCAL_QUORUM, EACH_QUORUM) ensure higher data consistency but may impact latency due to waiting for more nodes to return results (acknowledge). Conversely, lower consistency levels (ONE, LOCAL_ONE) provide higher latency but lower data consistency.
V. Anti-Entropy Mechanism
In distributed database systems, ensuring data consistency is crucial. Whether you’re using strong consistency or eventual consistency mechanisms, issues like network errors, connection failures, disk write errors, node failures, and others can lead to data inconsistencies across different nodes. To address this problem, several techniques have been developed, such as Hinted Handoff and Repair.
1. Hinted Handoff:
Hinted Handoff is a mechanism that helps ensure data is not lost in the event that some nodes are temporarily unavailable to receive new write data.
- For example, in a cluster with a replication factor (RF) of 3, the Coordinator node will identify the specific 3 nodes to store the data (operation write 1).

Hinted Handoff (1)
- If the node supposed to receive the write value is down, as illustrated in the diagram (Node X doesn’t send an Ack to the coordinator), and the consistency level requirement is met, the Coordinator node will send a response back to the client. Then, the Coordinator node will store a Hint value for the downed node.
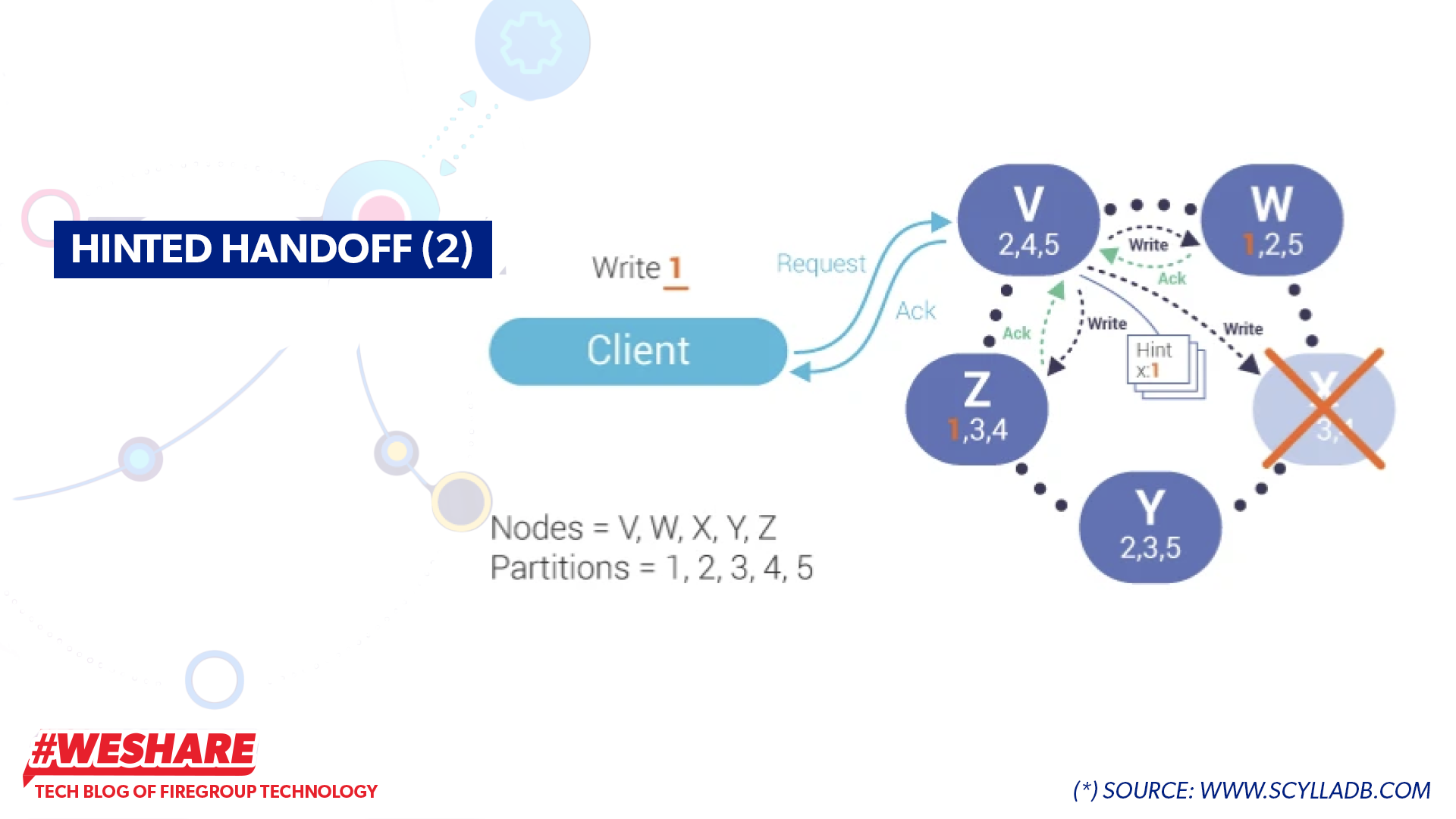
Hinted Handoff (2)
- When the downed node returns to a healthy state (up), the Coordinator node will resend the request to that node (Node X as shown in the diagram). If Node X sends an ACK back to the coordinator confirming the successful receipt of value 1, the Hint data will be deleted. The data replica is still preserved and maintained during this process.
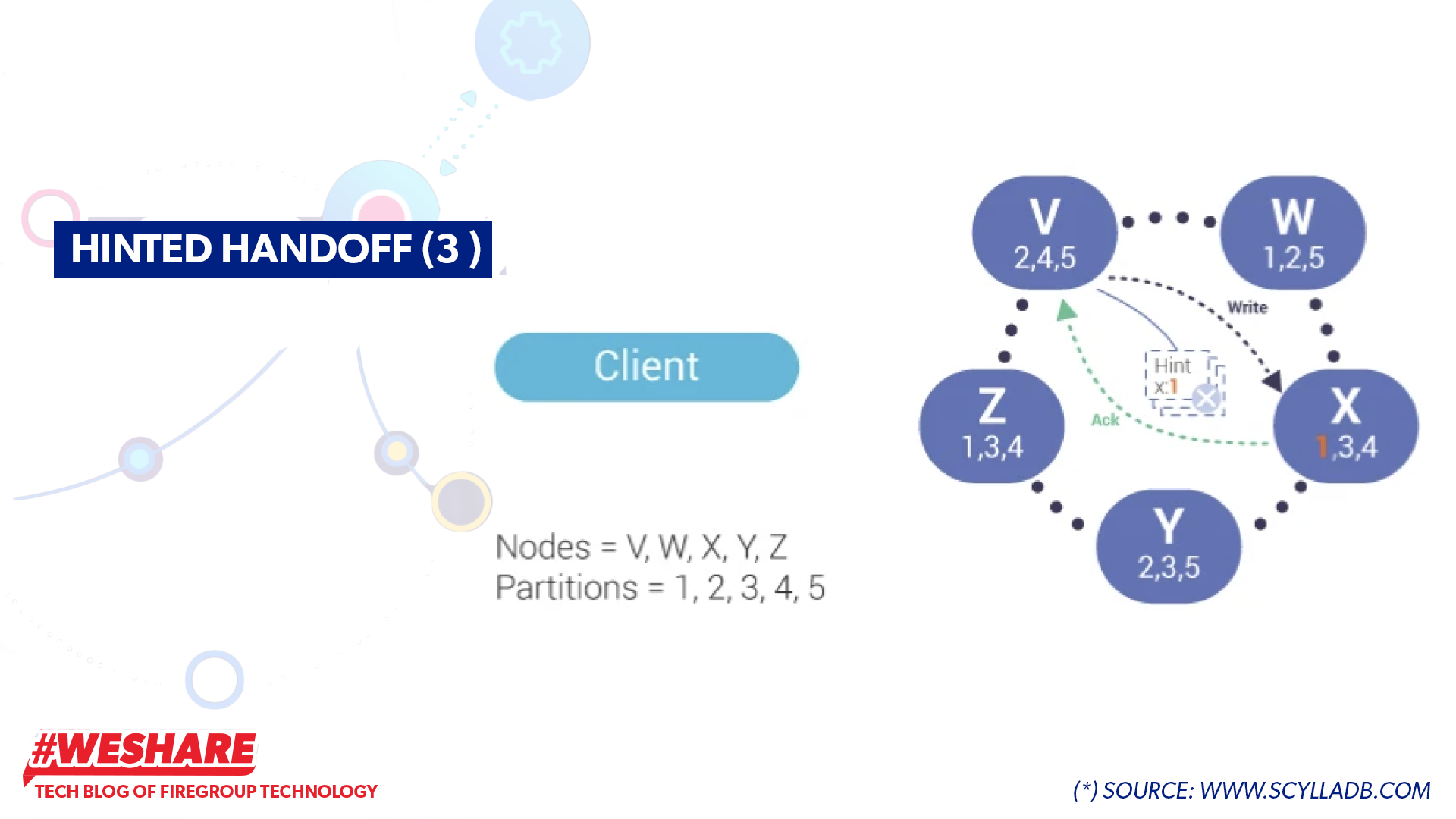
Hinted Handoff (3)
2. Repair
Replicas of data stored in nodes can become inconsistent with each other over time. Repair is a crucial mechanism in ScyllaDB that helps maintain data consistency among nodes in the cluster. The main purpose of Repair is to detect and fix errors in the data, ensuring that all nodes have the same data.
How it works:
- Identifying inconsistent replicas: ScyllaDB uses mechanisms to detect inconsistent data replicas across different nodes.
- Synchronizing data: When inconsistent replicas are detected, ScyllaDB copies the correct version of the data from other replicas and overrides the inconsistent replicas.
- Updating metadata: After data synchronization, ScyllaDB updates metadata related to the data replicas to mark them as repaired and consistent.
VI. Compaction Mechanism
Compaction is a crucial mechanism in ScyllaDB that optimizes performance and reduces storage space for data. Compaction works by merging multiple smaller SSTables into a larger SSTable. Here’s how it works:
- In a Scylla cluster, SSTables written to disk will grow over time due to ongoing operations.
- Scylla implements the compaction mechanism, which automatically runs continuously in the background to optimize storage space and database performance by merging smaller SSTables resulting from data fragmentation into larger ones, following these rules:
- SSTable Size: Scylla compresses SSTables when they reach the configured maximum size.
- Time: Scylla can compact SSTables after a specified period since their creation.
- Configuration: Scylla can be configured to compact SSTables based on specific rules in scylla.yaml, such as:
- Compacting all SSTables smaller than a certain size.
- Compacting SSTables older than a certain time.
- Compacting SSTables with high write ratios.
- By default, Scylla automatically uses the Size-TieredCompationStrategy (STCS) for compaction. The operation of this strategy is as follows:
- Scylla monitors the size of SSTable within a keyspace.
- When a sufficient number of SSTable with similar sizes (as configured in file config.yaml) are present, Scylla triggers the compaction process. For instance, all 64MB files will be grouped together, and similarly for 128MB files.
- Scylla merges smaller SSTable into larger ones, increasing in size order.
- This process repeats, gradually reducing the number of SSTable and increasing the average size of SSTable to optimize reads and avoid read amplification, where the database system reads more I/O than necessary for actual user queries from the client.
VII. Tombstones Mechanism
- When a record is deleted, Scylla doesn’t immediately delete the data from disk. Instead, Scylla creates a tombstone to mark the row/cell as deleted.
- Tombstones help synchronize data deletion across nodes, ensuring that when data is deleted from one node, the deletion is also synchronized across other nodes.
- During the compaction process, if a row is marked with a tombstone, it will be permanently deleted from the SSTable.
VIII. Summary
In this article, we have explored ScyllaDB – a distributed database system with extremely high processing performance, capable of scaling both horizontally and vertically with special architectures like shard-per-core, shared-nothing architecture, along with many automated optimization techniques and error self-healing capabilities. Below is a summary of the advantages and disadvantages of ScyllaDB:
1. Advantages of ScyllaDB:
- High scalability: ScyllaDB can utilize both vertical and horizontal scaling, making the system flexible and able to scale as needed.
- High availability: With a master-slave-free architecture, each node in the cluster is equal and capable of processing data and self-recovering in case of failures, ensuring high availability for the system.
- High performance: ScyllaDB is optimized to achieve maximum performance, nearly matching the hardware provided, improving response time and quickly responding to application requests.
- Flexible architecture: ScyllaDB utilizes share-nothing and shard-per-core architectures, maximizing hardware resources and achieving independence and equality among nodes in the cluster.
- Effective memory management: Using mechanisms like Memtable and SSTable along with optimized cache usage, ScyllaDB optimizes memory management and speeds up data retrieval.
2. Disadvantages of ScyllaDB:
- Complex configuration: Due to its many configuration options and complex settings, configuring and tuning the system can be challenging for new users.
- High skill requirements: Deploying and managing ScyllaDB requires deep knowledge of distributed systems and a profound understanding of the operational principles of NoSQL databases.
- Data replication and consistency management required: Although ScyllaDB provides mechanisms like data replication and consistency levels to ensure consistency and availability of the system, managing and configuring them requires attention and high skills to ensure consistency and meet latency requirements.
- Challenges in debugging: Due to the distributed and complex nature of the system, debugging and handling issues in ScyllaDB may require significant time and deep technical knowledge.
In the next article, where we delve into the application of Scylla Database within the operations of FireGroup, we will unveil some of the best practices employed by our DevOps Team. These practices are meticulously crafted to optimize the utilization of ScyllaDB, ensuring peak performance and streamlined workflows.
Written by Luc Dang Tan – DevOps Engineer, FireGroup Technology
Embrace the opportunity to be part of our cutting-edge projects and tech-driven journey, join us now at Our Career Page






